Chase is the #1 banking portal in the United States and is a comprehensive online platform that helps customers make payments, manage their money, and obtain information and encompasses Chase websites offering a wide range of banking and financial services to individuals, businesses, and institutions.
At JPMorganChase, the technology that powers Chase.com spans systems that can be accessed from the internal corporate network to systems that are visible to public internet devices and intersect with multiple network zones. It uses specific architecture approaches for each zone for security and network controls, to manage high-velocity internet traffic, and to filter untrusted traffic from trusted traffic. These concerns, common to all internet-based service providers, have led to highly scalable solutions across multiple regions using public cloud solutions.
We serve customers across multiple geographic regions and metros, and it is crucial to host services closer to where they physically are so we can provide an optimal user experience, reduce latency, and geographically distribute load balancing.
Understanding Multi-region Scaling
As the digital access point for millions of Chase customers, it is imperative that the Chase.com platform is always on 24/7/365 to provide critical banking services. To achieve this goal, multi-region “active-active” deployments are required with the following features and capabilities:
- Reliability: Aids in minimizing the impact of physical faults caused by infrastructure failures, adverse weather conditions, and cyber-attacks. They can also help with recovery time if a regional service fails.
- Data security: Improve data security and compliance by using data replication and backup mechanisms across regions to help ensure business continuity and minimize impact on customers if there is a security breach or data loss.
- Resilience: Can provide higher resiliency than single region applications. For example, a multi-region architecture can survive a regional failure, while a single region architecture can only survive zonal failures.
- Latency and performance optimization: Helps in solving the “last-mile problem.” Customer requests over the internet typically go through several hops to reach Chase data centers. This may be due to unoptimized network routes — this is called the last mile problem. By leveraging Points of Presence (POPs) closer to customers in many locations Chase optimizes network routes leading to lower latency.
- High availability: Provides flexibility to adapt to disruptions or unpredictable increases in traffic, making services highly available.
- Cost implications: Incurring an initial setup cost is more than offset by operational needs as disruptions are automagically handled, providing significant cost savings by being highly available.
Architecture
The architecture of Chase.com relies on the following tenets to design for multi-region deployment.
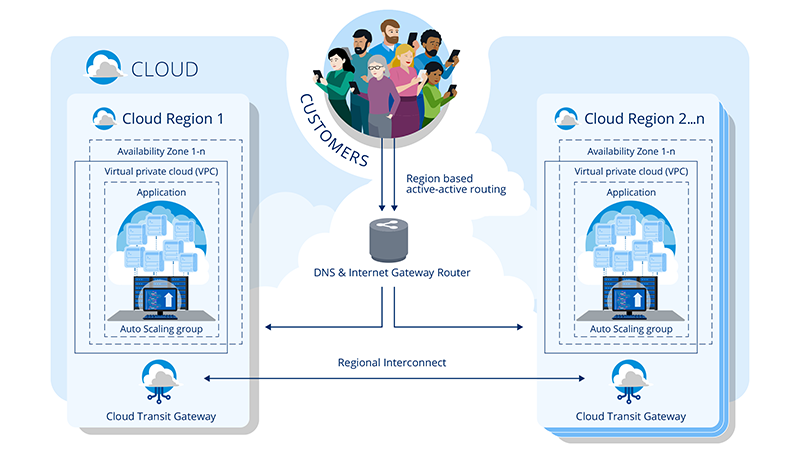
In the following infographic, the architecture behind how Chase.com is made available in multiple geographic regions via the cloud is depicted.
Short Description: Infographic showing how Chase customers’ devices are routed in the cloud to access Chase.com.
Long Description: The graphic portrays how customers’ devices are routed to cloud-based applications by region. First, multiple customers are shown with their devices which connect to a DNS and Internet Gateway Router.
Next, the devices are shown to be directed to one of multiple cloud regions available, each with its own Virtual Private Cloud within availability zones. Several servers are shown for each cloud region with a computer that represents each auto-scaling group connecting to the servers.
Finally, the infographic simultaneously depicts a Cloud Transit Gateway for each cloud region. The Cloud Transit Gateways are connected by a Regional Interconnect for multi-region deployment.
Load Balancing
Applications are typically grouped into zonal or regional deployments. Load balancing across these groups needs to be managed. The key considerations include the following:
- A single region can handle the entire workload volume and transactions.
- Stateless services — Applications do not store the “conversational” state of the users. They are offloaded to distributed caches or stores.
- Horizontal scalability — Applications must be able to scale horizontally. For example: CPU, Memory, requests per second (RPS), or another criterion.
- Identical services between regions — No region-specific application or infrastructure rollout.
Content Delivery
Static assets are segregated from API calls. This allows static assets to be offloaded at the edge using a Content Delivery Network (CDN) and caching assets on the device. Content delivery benefits from protecting origins from getting overwhelmed and enhancing performance by landing assets closest to customers.
DNS Management
Global and regional/zonal DNS servers for multiregional deployments for increasing availability and making Chase.com fault tolerant. The global servers resolve to regional servers with health check mechanisms built in that allow for uninterrupted services in case of regional outages. Regional health checks into endpoints provide a level of Quality of Service (QoS) to support degradation of services aggregated to a region and help shape traffic to regions that experience higher traffic.
Data Consistency and Replication
Our customers are located across the continental United States, covering many cities and metros. To serve them better our data centers are in multiple regions covering the major metros. This means customer data must always be available in all regions.
Caching
Web and Mobile traffic for Chase.com supports high volume and high transactions per second (TPS) traffic. Application caching is used to improve performance and protect upstream from being overwhelmed. Since customers remain in a particular region for the duration of a session it precludes the need to replicate cache between regions.
Challenges and Strategies (architectural solutions)
Chase.com is faced with challenges due to being the largest bank in the United States and a popular mobile app. The goal is to keep our services always available and performing for our customers to conduct their everyday banking needs.
Multi-region Setup
The key challenges to multi-region setup are:
- Failover mechanisms — resiliency and high availability
- Traffic shaping — performance-based routing
- Data consistency and replication challenges — CQRS pattern
Failover Mechanisms — Resiliency and High Availability: The application is configured with multiple Availability Zones (AZ) in a region for regional resiliency and multiple regions for global resiliency. Applications use all AZs in a region to maximize availability and are load balanced with QoS for performance by using load-feedback based routing.
The architecture allows for multiple AZ failures within a region as health checks are integrated into the applications, allowing for uninterrupted customer experiences.
The integrated health check can check for aggregated health of the entire region across AZs to give direct feedback to regional DNS servers about the entire region’s health. Health checks are configured with thresholds for failures and successes, allowing for automatically failing over to a new region if health check criteria deem the region unfit for servicing customers in that region. In this way, we can handle both scheduled maintenance activities in a single region or involuntary disruptions due to the degradation of critical components in a region at runtime.
Failing over to new regions is carefully orchestrated by distributing traffic on a failing or failed region across all healthy or available regions. This avoids the problem of thundering herds or overloading healthy regions with requests from a failed or failing region.
The pool of healthy regions is updated, allowing for traffic re-distribution when a failed region is brought back online. Among other things, the architecture allows for rolling out and testing deployments, updating, and patching components, and regional outages and draining requests to completion in cases where customers were already being served.
Traffic Shaping — Performance-based Routing: With smart traffic routing, such as going to the same region during the lifetime of a customer session, while asynchronously replicating state across regions, we can achieve performance-based load balancing while accommodating spike traffic without disruption to already logged in customers.
Data Consistency and Replication Challenges — CQRS Pattern: A customer may be active in one region at a time and any data changes need to be replicated to other regions. Most customer requests are read-heavy which allows us to use CQRS patterns to split read vs write workloads. This allows read traffic to be served with affinity to a region. The complexity remains with write workloads and replicating updates to other regions.
Monitoring and Observability: Observe and act automagically to keep Chase running 24/7/365 days a year.
Aggregation at All Levels — Automated Mechanism and Controls Failover at Various Levels: A holistic view is made from signals gathered from all zonal/regional levels with criteria set to automate. First, we get critical metrics for infrastructure emitted from each node and components in each node. Second, we proactively get the healthy status of our back ends. Thirdly, health checks monitor the status of the alternate region(s) again proactively.
There are actions associated with monitored components, for example, to kick off auto-healing or send alarms to critical operations folks in case manual interventions are required. Operations have associated run books and protocols laid out to triage issues if required.
This gives us observability, i.e., knowing proactively why and what components are under duress and if action is required while minimizing customer impacts as in-place actions minimize customer impacts.
Gray Failures: Chase’s approach is to have deep health checks run asynchronously in the background to detect and respond to failures. Typical implementations of health checks include major system failures and ignore certain paths that can impact customer experience, which falls into what is known as gray failures. For example, if a network connectivity failure occurs on a single availability zone (AZ) and applications in that AZ are blocked from accessing critical resources like databases or other services while other AZs continue to function, typical health checks may not detect failures since not all requests fail. By integrating health checks at the AZ level to detect failures we can take the AZ out of route so that no new requests would land on the unhealthy AZ.
Conclusion
Being always available requires a significant architectural investment that isolates failures and prevents global outages.
A robust site does not assume that all components work all the time. Instead, it relies on being available holistically by containing the blast radius of its failing parts via isolations, circuit-breakers, thresholds, monitoring, and automated observability actions associated with them.
A multi-region setup is complex and requires a well-architected framework and investment. However, it is also the only option that provides the highest availability of services to millions of our valued customers.
At Chase, we offer many products to our customers that are used in their daily lives. Any interruptions to those services will have a negative impact on our customers. To keep these services up and running all the time is our collective responsibility and we strive to build systems and processes to meet that goal.
Richard Hultstrom, Managing Director of Software Engineering, and Monish Unni, Executive Director and Principal Architect, contributed to this article.
For Informational/Educational Purposes Only: The opinions expressed in this article may differ from other employees and departments of JPMorgan Chase & Co. Opinions and strategies described may not be appropriate for everyone and are not intended as specific advice/recommendation for any individual. You should carefully consider your needs and objectives before making any decisions and consult the appropriate professional(s). Outlooks and past performance are not guarantees of future results.
Any mentions of third-party trademarks, brand names, products and services are for referential purposes only and any mention thereof is not meant to imply any sponsorship, endorsement, or affiliation.